
Learn DynamoDB by running it - accesspatterns.dev
I've been building on DynamoDB since around 2015, and these days I build tools for it: dynoxide, a DynamoDB engine, and Nubo, a native client. So I'm not neutral about it. It's the first database I reach for, and with reason - the operational overhead is close to nil, no connections to pool or instances to size, and it holds the same single-digit-millisecond reads whether the table has a thousand items or a billion. The data modelling is a craft, and a satisfying one.
It's also one of the harder databases to learn, and that's the part I keep coming back to. DynamoDB punishes the instincts you bring from SQL. You don't normalise and join at read time; you work out the questions your app will ask first, and shape the data around those access patterns, until one table answers all of them. It's a real shift in how you think, and it's where a lot of people bounce off - it feels backwards right up until it clicks.
The people who teach it best all teach it the same way. Alex DeBrie's The DynamoDB Book, the arc.codes team's examples, Rick Houlihan's re:Invent talks - the legendary ones, where he models half a dozen access patterns onto a single table at a hundred miles an hour - none of them hand you rules to memorise. They show you patterns and make you run them. I learned a lot of my DynamoDB from all three, and it stuck because I was building as I went.
That last part is the bit that's hard to come by on your own. Reading about an access pattern and having it in your fingers are different things, and to run one - build the table, write the items, fire the query and see what comes back - you need an AWS account, or a local emulator installed and seeded. Enough friction that plenty of people read about single-table design without ever building one.
There was a second thing pulling the same way. dynoxide had learned to run in the browser only last month, compiled to WebAssembly with no server behind it, and it was a preview I didn't fully trust. What it needed was a real, demanding consumer: something that would lean on the wasm engine hard enough to find where it broke, not a handful of tests that politely agreed with it.
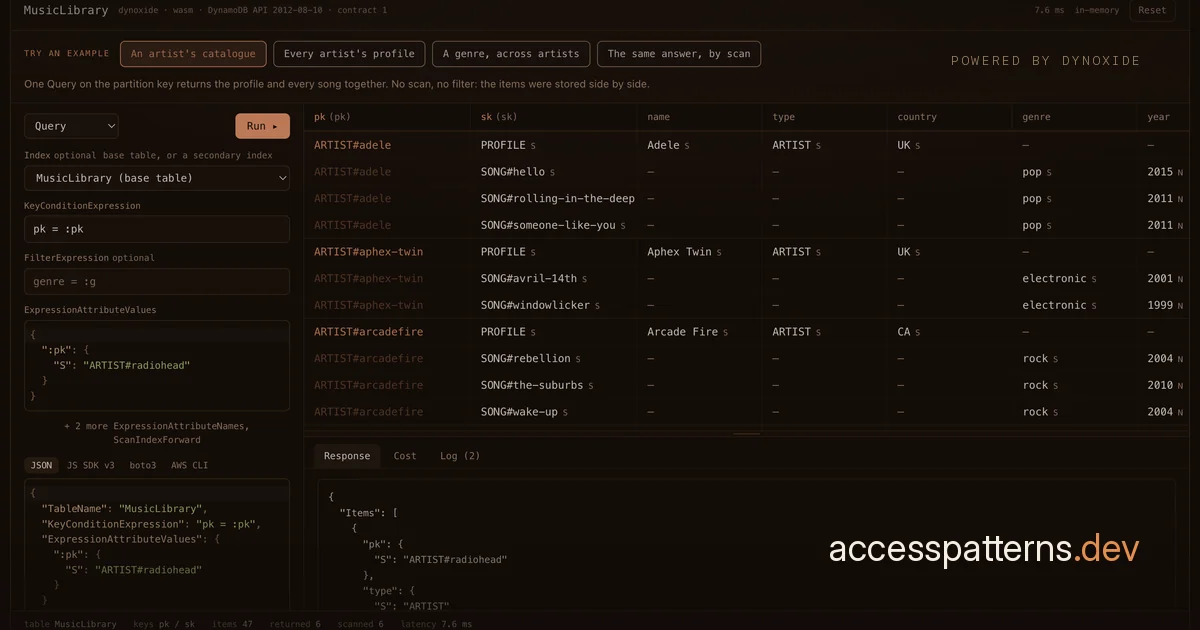
Both of those pointed at the same project, and accesspatterns.dev is what came out of it: a place to learn DynamoDB that also happens to be a working app sat on the engine all day. That's where the past month went, and why 0.11.0 took as long as it did - building on it in earnest is what turned up the bugs that release fixed.
What you get out of it is the thing I wanted from the start: the friction is gone. Open the page and the engine is already there with a table in it. Query one customer's orders and you get exactly those back, because in DynamoDB the key is the address; run the same question as a scan and it reads the whole table and throws most of it away. Same answer, very different work, and you've seen it for yourself rather than taken it on trust.
There's more to it than that, though. A course of about twenty lessons takes you from your first GetItem to single-table design, each one something you build and try rather than just read. Beyond it sit a handful of worked models - a game leaderboard, a SaaS multi-tenant table - to load up and pick apart, closer to what you'd actually ship than the usual textbook example. And underneath everything is a full console: assemble any operation, fire it at the table, and lift the request straight out as JavaScript SDK v3, boto3 or AWS CLI code for your own app.
How it works
It all runs on dynoxide compiled to WebAssembly, in a Web Worker in your tab: the same engine that backs the native build, the same SQL underneath, now packaged on npm as the thing accesspatterns.dev depends on. There's no backend, so every query, scan and write runs client-side against a SQLite-backed store. The database is in the tab, which is why it needs no account and nothing to install.
It's a preview. The wasm build doesn't yet run against the conformance suite that holds dynoxide's native build to real DynamoDB, so treat what you see as illustrative rather than authoritative. Building accesspatterns.dev on it is what's been hardening it; getting the wasm engine onto that suite is the next job, and the day it's there is the day the preview label comes off.
It's early, and the part I most want to grow is that library of models. I'd rather it weren't only mine. A shared, runnable catalogue of how people actually model their own problems on DynamoDB would be worth far more than my handful of examples, and that's the direction I want to take it. There's no way to submit one yet, but if you've got a pattern you'd want in there, tell me - and if something behaves wrong, tell me that too. It's the same dogfooding that got the engine this far.